전체 글
-
redis를 통해 로그아웃 기능 구현2023.11.27
redis를 통해 로그아웃 기능 구현
Redis
Redis는 오픈 소스 기반의 비관계형 DBMS로, Key-Value 구조의 비정형 데이터를 저장하고 관리한다. 이는 우리가 흔히 사용하는 MySQL과는 다르게, 인메모리 데이터 구조를 가진 저장소이다.
MySQL과 같은 전통적인 DB는 데이터를 디스크에 저장한다. 이로 인해 서버가 다운되더라도 데이터는 보존되지만, 데이터를 조회할 때 디스크에서 읽어야 하므로 속도 면에서 불리하다. 반면, Redis는 자주 사용되는 데이터를 메모리에 저장하여 빠른 데이터 접근 속도를 제공한다.
따라서 이번 프로젝트에서는 Redis를 활용하여 사용자의 로그아웃 시 발급된 JWT 토큰을 저장하고, 이를 BlackList로 관리한고, JWT 토큰의 유효 시간 동안 해당 토큰을 Redis에 보관함으로써, 로그아웃 후 토큰이 탈취되더라도 해당 토큰을 악용할 수 없게 했다.
1. Docker를 통해 Redis 실행하기
docker pull 을 사용하여 Redis 이미지 다운받기
docker pull redispull 받은 이미지로 docker Container 실행하기
sudo docker run -d --name redis -p 6379:6379 redis
여기까지 성공했다면
docker ps -a 명령어를 통해 실행중인 컨테이너에 아래와같이 redis를 실행하는 컨테이너가 생길것이다.

2. yml 파일 작성하기
본 프로젝트는 profile 을 사용하여 각 환경에 필요한 yml 파일을 읽게한다.
application.yml 파일은 아래와 같다.
spring:
profiles:
group:
local: localDB, jasypt, oauth, mybatis, aws, redis
prod: prodDB, jasypt, oauth, mybatis, aws, redis
test: testDB, jasypt, oauth, mybatis, aws, redis
active: local
application-redis.yml 에 아래와 같은 정보를 저장한다.
redis:
pool:
min-idle: 0
max-idle: 8
max-active: 8
port: 6379
host: 127.0.0.1 // spring boot 는 따로 container로 실행하지 않았을때
만약 spring 서버도 독립적인 container에서 실행되고 있다면 docker-compose 에서 host 이름을 지정해준다음 위 yml 파일 host에 지정해준 이름을 넣어주면 된다.
3. RedisProperties 클래스를 정의
@Component
@ConfigurationProperties(prefix = "redis")
@Getter
@Setter
public class RedisProperties {
private int port;
private String host;
}
해당 클래스를 통해 우리가 yml에서 지정해준 port 및 host 정보를 가져온다.
@ConfigurationProperties 를 사용하면 application-redis.yml 에 정의한 redis.host 와 redis.port 설정 정보를 가져와 RedisProperties 에 바인딩 한다.
4. RedisConfig 를 정의한다.
@RequiredArgsConstructor
@Configuration
@EnableRedisRepositories
public class RedisConfig {
private final RedisProperties redisProperties;
@Bean
public RedisConnectionFactory redisConnectionFactory() {
return new LettuceConnectionFactory(redisProperties.getHost(), redisProperties.getPort());
}
@Bean
public RedisTemplate<String, Object> redisTemplate() {
RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(redisConnectionFactory());
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setValueSerializer(new StringRedisSerializer());
return redisTemplate;
}
}
RedisConfig 클래스를 통해 우리가 원하는 Redis의 설정정보를 구성해준다. 여기서 설정해준 정보를 통해 Redis 와의 연결 및 데이터 처리방식을 제공한다.
@EnableRedisRepositories: Redis를 사용한 데이터 접근을 위해 Spring Data Redis 리포지토리를 활성화한다.redisConnectionFactory(): Redis와의 연결을 위한ConnectionFactory를 생성한다. 여기서는 Lettuce 라이브러리를 사용하여 연결을 생성한다.redisTemplate(): Redis 데이터 작업을 위한 중심적인 클래스인RedisTemplate을 정의한다. 이 메서드에서는 키와 값의 직렬화 방식을StringRedisSerializer로 설정했다.LettuceConnectionFactory: Lettuce는 Redis 클라이언트 중 하나로, 비동기 이벤트 기반의 연결을 제공한다. 여기서는RedisProperties에서 제공하는 호스트와 포트 정보를 사용하여 연결을 생성한다.StringRedisSerializer: 이 직렬화 방식은 Redis의 키와 값으로 문자열을 사용하려는 경우에 사용한다.
RedisConnectionFactory
역할:
RedisConnectionFactory는 Redis 서버와의 연결을 관리하는 인터페이스다. 이 인터페이스를 구현한 클래스는 Redis 서버와의 연결 세션을 생성하고 관리한다.Lettuce 라이브러리:
- Lettuce는 Redis 클라이언트 중 하나로, 네티(Netty) 기반의 비동기 이벤트 구동 모델을 사용한다.
- 여러 Redis 노드 구성(예: Sentinel, Cluster)을 지원하며, 연결 풀링이 내장되어 있어 고성능 환경에서도 잘 동작한다.
LettuceConnectionFactory는 Lettuce 클라이언트를 사용하여 Redis 서버와의 연결을 생성하고 관리한다.
RedisTemplate
역할:
RedisTemplate는 Redis와의 데이터 작업을 추상화하여 제공하는 헬퍼 클래스이다. Redis의 데이터 구조와 명령을 Java 객체와 메서드로 매핑하여, Java에서 Redis 작업을 쉽게 수행할 수 있게 해준다.직렬화:
- Redis는 바이트 배열 형태로 데이터를 저장한다. 따라서 Java 객체를 Redis에 저장하거나 조회할 때는 객체를 바이트 배열로 변환하거나 바이트 배열을 객체로 변환하는 작업이 필요하며, 이러한 작업을 직렬화(Serialization) 및 역직렬화(Deserialization)라고 한다.
RedisTemplate에서는 키와 값의 직렬화 방식을 설정할 수 있다. 예를 들어,StringRedisSerializer는 문자열 데이터를 바이트 배열로 변환하는 직렬화 방식이다.
활용:
RedisTemplate를 사용하면, Redis의 기본 데이터 구조(예: String, List, Set, Hash, ZSet)에 대한 연산을 Java 메서드로 쉽게 수행할 수 있다. 또한, 트랜잭션, 파이프라인, 스크립트 실행 등의 고급 기능도 지원한다.
5. Redis Util 정의
최종적으로 RedisUtil 이라는 클래스를 통해 특정 메서드를 사용하여 Redis 에 작업을 할수있게하는 클래스를 정의해준다.
@Component
@RequiredArgsConstructor
public class RedisUtil {
private final RedisTemplate<String, Object> redisBlackListTemplate;
public void setBlackList(String key, Object o, int minutes) {
//Redis에 저장할 데이터 방식을 설정
redisBlackListTemplate.setValueSerializer(new Jackson2JsonRedisSerializer(o.getClass()));
//Redis의 String타입 구조에 작업을 수행하기 위한 연산
redisBlackListTemplate.opsForValue().set(key, o, minutes, TimeUnit.MINUTES);
}
public boolean hasKeyBlackList(String key) {
return Boolean.TRUE.equals(redisBlackListTemplate.hasKey(key));
}
}
여기까지 했다면, RedisUtil 클래스의 setBlackList 메서드를 통해 우리가 원하는 토큰을 지정해준 시간이 지날때까지 Redis 에 보관을 하며, Redis 에 존재하는 JWT 토큰으로 로그인을 한 상태를 유지할수 없게 만든다.
setBlackList 메서드:
Jackson2JsonRedisSerializer: Jackson 라이브러리를 사용하여 Java 객체를 JSON 형식으로 직렬화하거나 JSON을 Java 객체로 역직렬화하는 직렬화 방식이다. 여기서는 저장하려는 객체의 클래스 타입을 기반으로 직렬화 방식을 설정하고 있다.opsForValue().set(key, o, minutes, TimeUnit.MINUTES): Redis의 String 데이터 구조에 값을 저장하는 메서드이다. 지정된 키, 값, 만료 시간, 시간 단위를 사용하여 데이터를 저장한다.
- hasKeyBlackList 메서드: 지정된 키가 Redis에 존재하는지 확인하는 메서드이다.
Boolean.TRUE.equals()를 사용하여 결과가true인지 확인하고 있다.
6. Redis 내부 데이터 확인하기
Redis를 실행중인Container내부에 들어가기docker exec -it redis /bin/bashRedis에 접속하기redis-cliRedis에 저장된key확인하기keys *특정
key에대한 만료시간 확인하기ttl <key>
위 명령어를 통해 redis에 저장된 토큰을 확인할수 있으며, 해당 토큰을 통해 로그인을 하려할때 filter 를 통해 로그인을 막을수 있다.
'Spring' 카테고리의 다른 글
| [Spring] Enum 타입으로 Exception 구현하기 (0) | 2024.07.22 |
|---|---|
| docker hub 사용하는 방법 (1) | 2023.11.27 |
| Jasypt 를 통한 암호화 (2) | 2023.11.27 |
| checkedException, uncheckedException (1) | 2023.11.22 |
| Transactional을 통한 rollback시 AUTO_INCREMENT 초기화 문제 (0) | 2023.07.06 |
Jasypt 를 통한 암호화
사용 이유
yml 파일에 DB에 연결해야할 민감한 정보가 있어 github에 올릴때 항상 해당 yml파일을 삭제했다.
근데 팀원이 jasypt를 사용하여 간단하게 평문으로 작성한 yml 파일을 암호화 할수 있다 알려줘 시도해보려고 했다.
Jasypt
Jasypt는 Java의 라이브러리로, 텍스트, 이미지, 바이너 데이터, XML등 다양한 형태의 데이터를 암호화하고 해독할수 있게 해준다.
또한 생각보다 다양한 암호화 알고리즘을 지원하며, AES, DES, RSA 등을 사용하여 암호화 할수있다.
이번에는 PBE (Password-Based-Encryption)을 사용하는 알고리즘인 PBEWithMD5AndTripleDES 을 사용하여 평문을 암호화할 생각이다.
1. gradle에 Jasypt 의존성 추가하기
implementation 'com.github.ulisesbocchio:jasypt-spring-boot-starter:3.0.5'
2. yml 파일에 Jasypt 설정 추가
jasypt:
encryptor:
iv-generator-classname: org.jasypt.iv.NoIvGenerator
algorithm: PBEWithMD5AndTripleDES
password를 yml에 작성했을때 password 지우는걸 깜빡할수 있기때문에 외부설정(VM)을 통해 추가하기로 했다.
3. VM을 통해 password 설정하기
아래와 같은 test코드를 통해 우리가 원하는 평문을 암호화 할 것이다.
단순히 암호화 할 내용에 암호화 하고싶은 내용을 넣어주면 된다.
@SpringBootTest
class IssueTrackerApplicationTests {
@Autowired
StringEncryptor stringEncryptor;
@Test
void contextLoads() {
//암호화
String encrypt = stringEncryptor.encrypt("암호화 할 내용");
System.out.println("암호화된 내용 = " + encrypt);
//복호화
String decryptedString = stringEncryptor.decrypt("복호화 할 내용");
System.out.println("복호화된 내용 = " + decryptedString);
}
}
test 코드로 진행할때 junit에 VM을 통해 jasypt 를 암호 및 복호화할 password 를 설정해줘야 하는데 설정방법은 다음과 같다.
4. Junit에 VM설정하기
일단 intellij settings에 들어가 Run tests using 을 Intellij 로 바꿔준다.
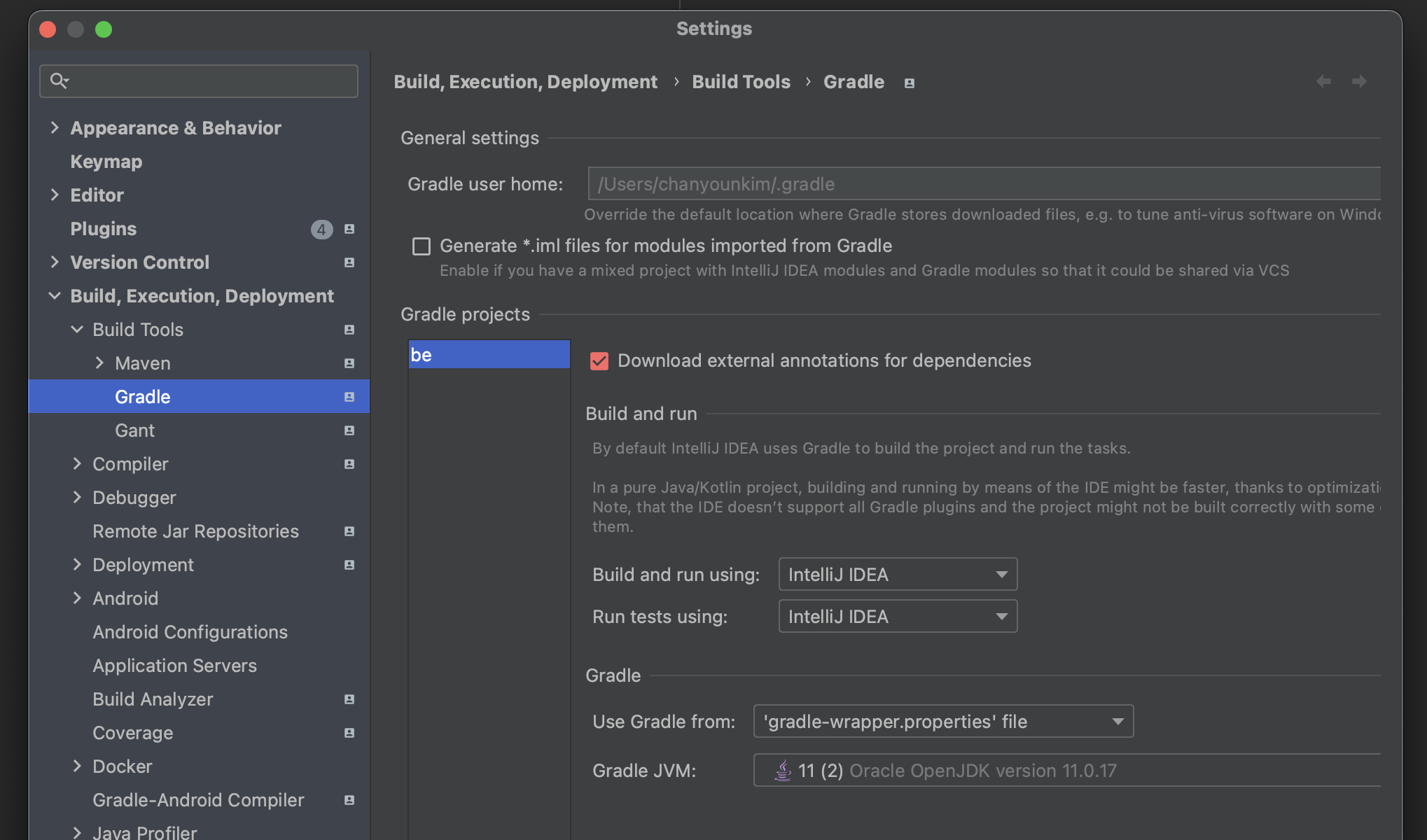
이렇게 설정을 바꾸게되면 테스트코드 실행시 Junit을 통해 실행하게 되는데, 이때 오른쪽 상단에 존재하는 edit configurations.. 에 들어가준다.
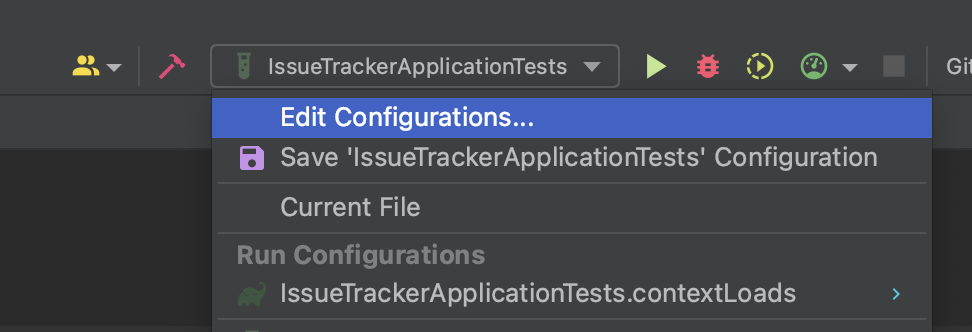
그후 왼쪽 하단에 있는 Edit configuration templates 를 눌러 Junit에대한 VM을 설정해주면 된다.
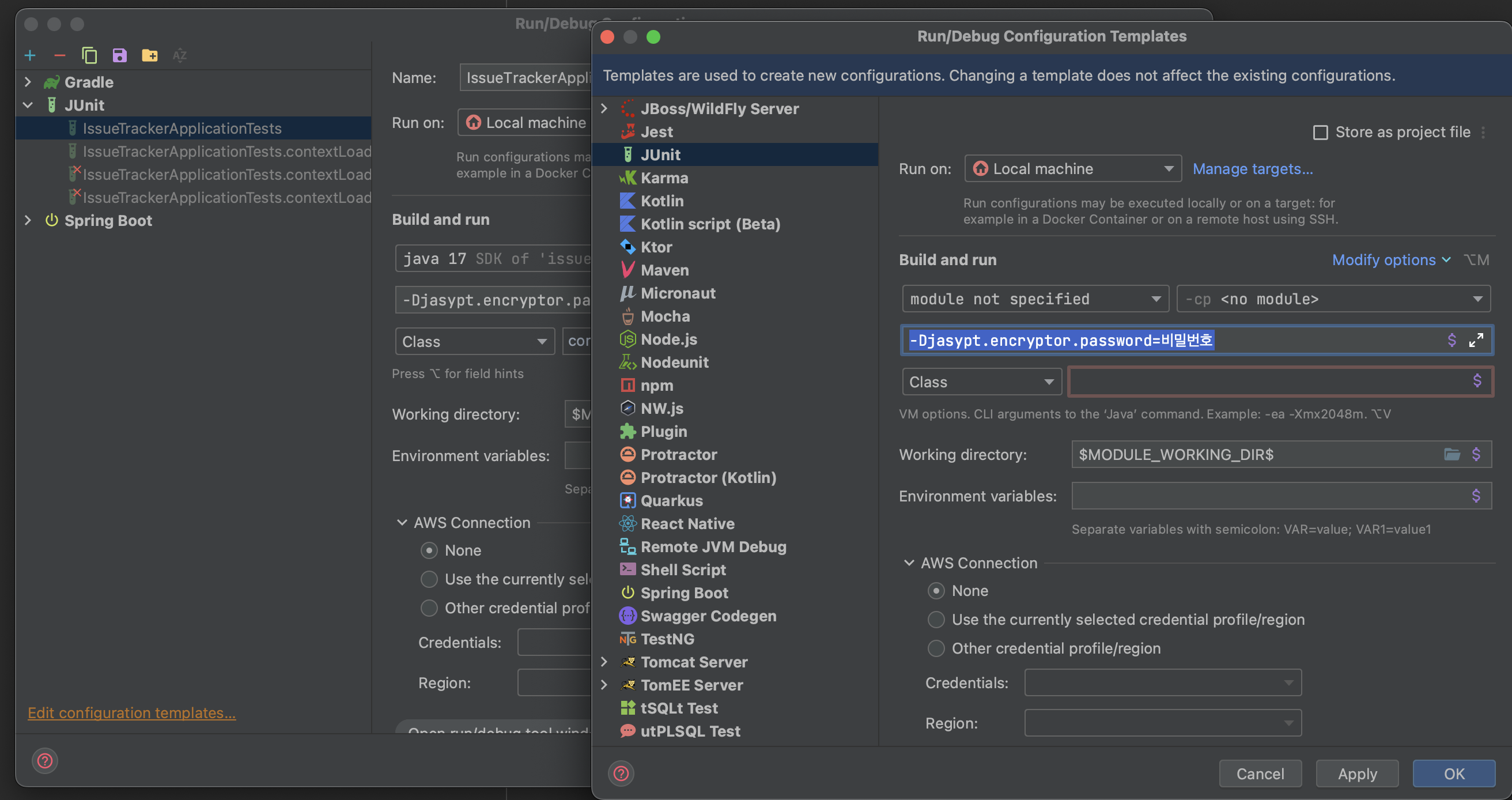
VM에 password를 넣는 형식은 아래와 같다.
-Djasypt.encryptor.password=비밀번호
이때 만약 VM을 넣는 칸이 없다면 Modify options 를 눌러 Add VM Options 를 클릭해 VM을 넣을수 있는 칸을 추가해주자.
이렇게 VM까지 설정을 해 주었다면 아래와 같은 test코드를 통해 평문을 암호화 하면 된다.
@SpringBootTest
class IssueTrackerApplicationTests {
@Autowired
StringEncryptor stringEncryptor;
@Test
void contextLoads() {
String encrypt = stringEncryptor.encrypt("암호화 할 내용");
System.out.println("암호화된 내용 = " + encrypt);
}
}
암호화 할 내용 에 암호화할 평문을 넣어주고 테스트를 실행하면 결과창에 암호화된 내용이 나오게 된다.
예를 들어 Application.yml에 존재하는 MySql 연결에 필요한 url을 암호화한다고 했을때 결과는 아래와 같다.
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: ENC(FqsfaB7VH3b02cmEcA7KnxoD/ka7bdJuI96EOmDc0ll0rq5kR51OxaUgub3w9j2+J6fpn+coGLEicAzsp8cPFvLdQHjRP0xWrK7+ZPyliLp58BPtgAKSC8nWePGmgAYNTLBMIQWZUekLOHMv)
username: ENC(emlpBQxxnd)
password: ENC(KDNBYKmj3c8n)
이렇게 ENC 표기후 괄호안에 테스트코드를 통해 암호화된 내용을 넣어주면 추후 VM에 존재하는 Password를 통해 복호화가 가능해져, 우리가 해당 yml 파일을 github에 올리더라도 password를 외부로 유출하지 않으면 보안상 안전하게 된다
'Spring' 카테고리의 다른 글
| docker hub 사용하는 방법 (1) | 2023.11.27 |
|---|---|
| redis를 통해 로그아웃 기능 구현 (0) | 2023.11.27 |
| checkedException, uncheckedException (1) | 2023.11.22 |
| Transactional을 통한 rollback시 AUTO_INCREMENT 초기화 문제 (0) | 2023.07.06 |
| @JdbcTest (0) | 2023.07.05 |
Docker를 통해 Mysql 설치
Mac에 Docker 깔기
brew 를 통해 Docker 깔기
brew install --cask docker
그후 아래 명령어를 통해 잘깔렸는지 확인해보기
docker -v
Docker에 Mysql 깔기
docker의 이미지 저장소에서 MySQL의 Docker 이미지를 로컬 시스템으로 다운로드 하기
docker pull mysql //버전을 지정하고 싶다면 docker pull mysql:버전다운받은 docker 이미지 확인하기
docker images
MySQL Docker 컨테이너 생성 및 실행하기
docker run --name <컨테이너명> -e MYSQL_ROOT_PASSWORD=<password> -d -p 3306:3306 mysql:latest생성된 컨테이너 리스트 확인하기
docker ps -a<이때 우리가 받은 Image를 기반으로 생성된 Container가 보이면 된다>
DBeaver2 에 연결시 오류 해결
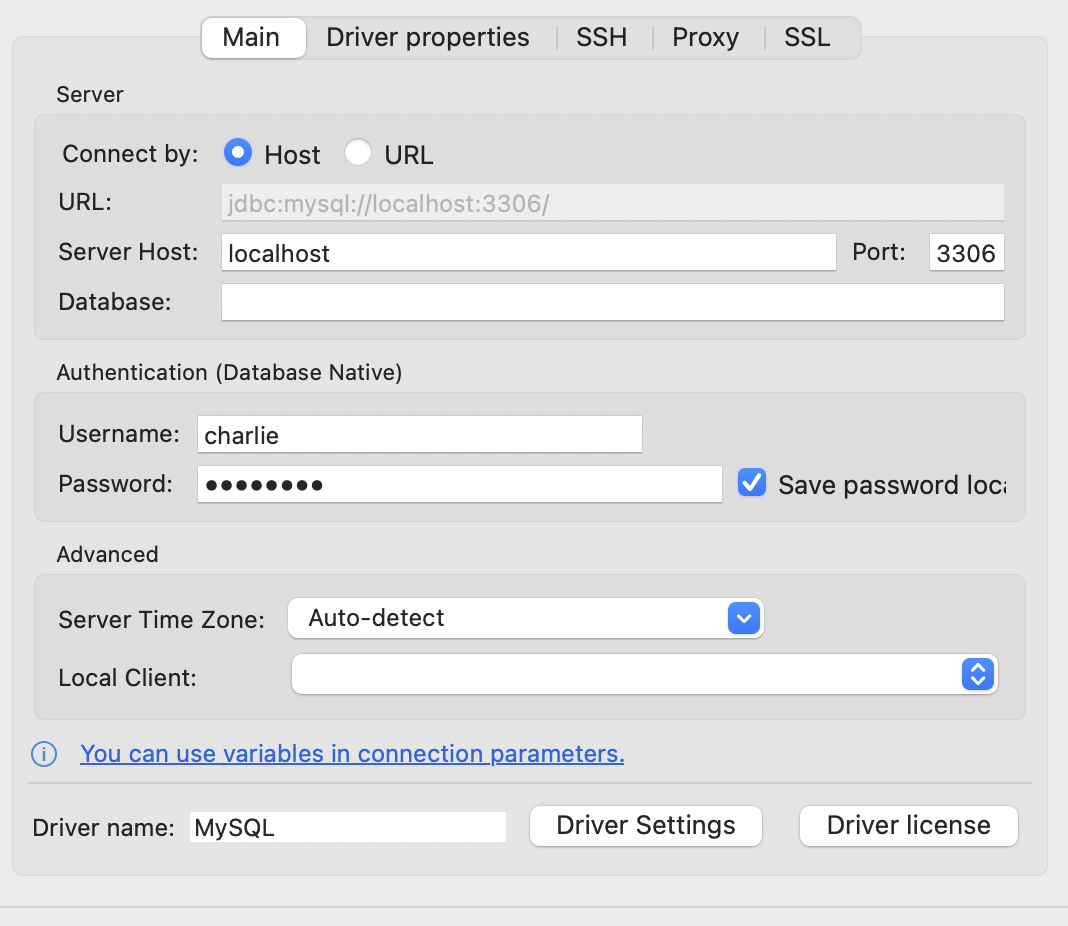
이런식으로 연결을 했는데 계속해서 Public Key Retrieval is not allowed 오류가 발생했다.
이때 Driver properties 에 추가정보를 제시하면 되는데 Driver Properties에 들어가서
allowPublicKeyRetrieval = true 로 설정해주면 연결에 성공한다.
'DB' 카테고리의 다른 글
| h2 DB 연결 방법 (1) | 2023.11.27 |
|---|---|
| 트랜잭션(transaction) (1) | 2023.11.22 |
| 커넥션 풀 및 데이터 소스 (0) | 2023.10.25 |
| JDBC (0) | 2023.10.25 |
| MySQL) 프로시저를 사용하여 더미 데이터 만들기 (0) | 2023.05.04 |
h2 DB 연결 방법
H2 DB 사용 방법
1. H2 DB 다운로드
h2 해당 사이트에 접속후 Download 에 들어가 운영체제에 맞는 h2 DB 를 다운받아준다.

Spring 을 사용하면 굳이 h2 DB 를 다운받지 않고 의존성만 추가해주면 사용할수 있지만, 이렇게하면 서버를 키지 않았을때 console에 접속할수가 없어 h2 DB를 다운받아 진행했다.
2. h2 실행
다운받은 h2 파일 안 h2/bin 에 들어가면 h2.sh 라는 파일이 있는데 해당 파일을 통해 h2 서버를 실행할수 있다.
터미널을 통해 h2/bin 디렉토리로 이동후 h2.sh 를 실행해준다.

이때 해당 파일을 실행할 권한이 없을수 있는데, 아래와 같은 명령어를 통해 실행 권한을 추가하면 된다.
chmod +x h2.sh
실행을 완료했다면
위와같은 콘솔창이 뜨게된다.
3. DB 생성
그후 평소처럼 사용하려고 했는데 다음과 같은 오류가 발생했다.
Database "/Users/chanyounkim/test" not found, either pre-create it or allow
remote database creation (not recommended in secure environments)
찾아보니
내가 사용하는 h2 의 2.2.224 버전에서는 db를 자동생성하지 않는다. 구버전으로 다운그레이드 하면 자동생성을 해준다는데 일단은 2.2.224 에서 db 를 생성해 사용하기로 했고, db 생성 방법은 아래와 같다.
h2를 터미널을 통해 실행을 했다면 오른쪽 위에 h2 아이콘이 있을텐데, 아이콘 클릭후 create a new database 를 누르면 다음과 같은 창이 뜬다.
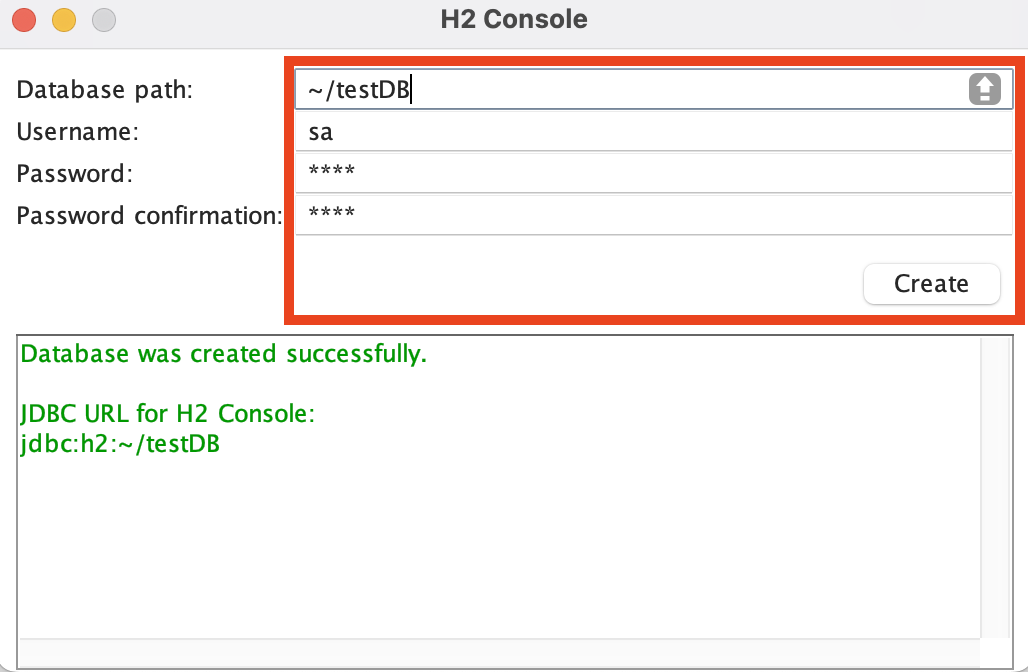
해당 이미지에 Database path, Username, password 를 원하는데로 입력하면 된다. 나는 home directory 에 만들고 싶어 경로를 다음과 같이 설정했다. ~/testDB
그후 터미널을 통해 확인해보면

우리가 만들어준 testDB.mv.db 가 존재하는것을 확인할수 있다.
4. DB 접속
DB까지 만들었다면 해당 DB에 접속을 하면 된다.
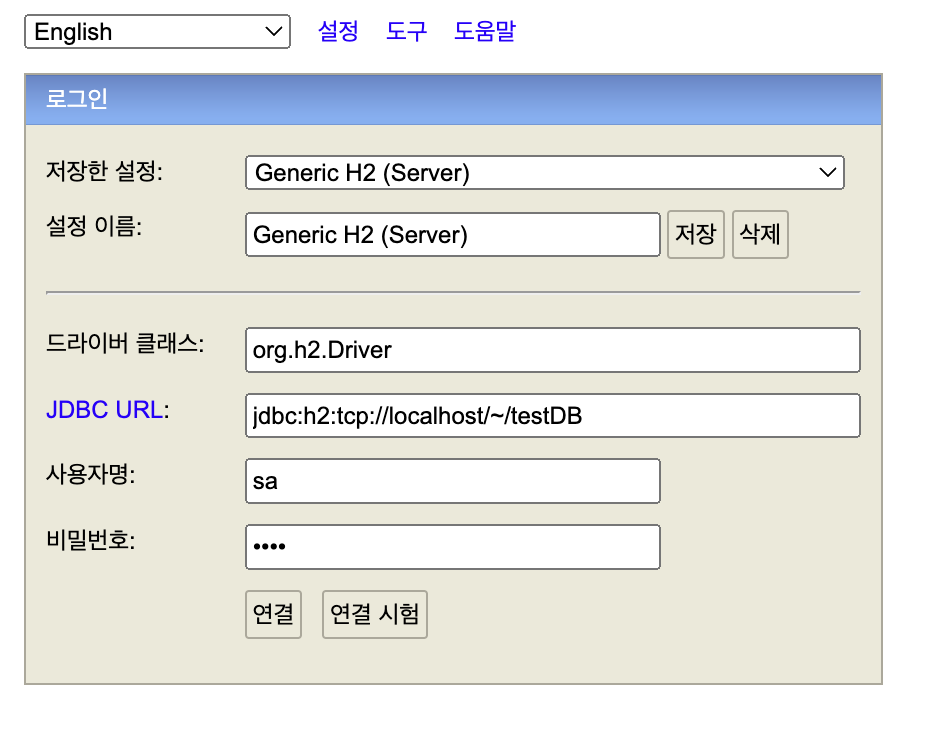
JDBC URL 에 testDB.mv.db 가 있는 경로를 지정해주고 연결을 누르면 연결이 잘되는 것을 확인할 수 있다.
'DB' 카테고리의 다른 글
| Docker를 통해 Mysql 설치 (1) | 2023.11.27 |
|---|---|
| 트랜잭션(transaction) (1) | 2023.11.22 |
| 커넥션 풀 및 데이터 소스 (0) | 2023.10.25 |
| JDBC (0) | 2023.10.25 |
| MySQL) 프로시저를 사용하여 더미 데이터 만들기 (0) | 2023.05.04 |
checkedException, uncheckedException
예외 계층
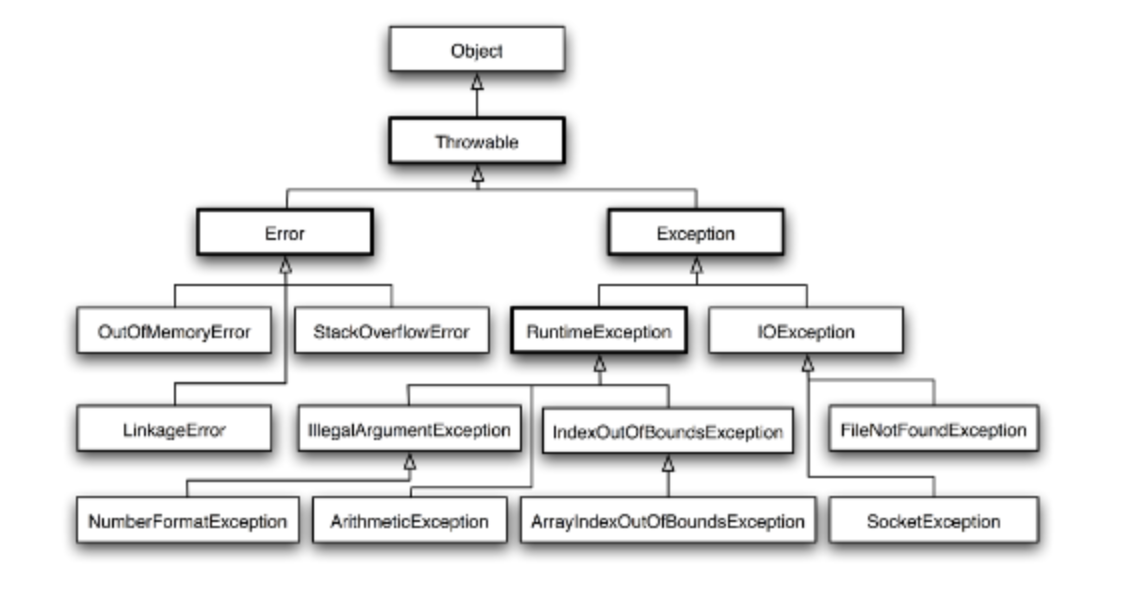
Error는 일반적으로 프로그램 자체에서 처리할 수 없는 심각한 문제다. Error는 일반적으로 하드웨어 또는 시스템 문제와 같은 외부 요인으로 인해 발생하며, 이로 인해 프로그램이 갑작스럽게 종료될 수 있다. Java에서 발생하는 Error의 예로는 OutOfMemoryError 와 StackOverflowError가 있다.
반면에 Exception은 프로그램 자체에서 처리할 수 있는 덜 심각한 문제다. Exception는 프로그램 로직의 오류 또는 잘못된 사용자 입력이나 네트워크 연결 실패와 같은 실행 중 예기치 않은 조건으로 인해 발생한다. Exception는 try-catch 블록을 사용하여 프로그램에서 포착하고 처리할 수 있으며, Java에서 Exception의 예로는 NullPointerException(RuntimeException의 자식 클래스)과 IllegalArgumentException이 있다.
- Exception 은 Checked Exception과 Unchecked Exception이 있다. Checked Exception은 try-catch블럭을 사용해 개발자가 예외처리를 직접해야 하지만 Unchecked Exception은 개발자가 예외를 처리해주지 않아도 컴파일 오류가 발생하지 않는다. (물론 try-catch block을 사용해서 예외를 처리해도되지만 강제되지 않는다는것이다).
- Unchecked Exception의 예로 RuntimeException이 있다. RuntimeException의 자식 클래스들 또한 Unchecked Exception이다.
예외는 발생한 곳에서 처리하지 못하면 밖으로 던져줘야 한다.
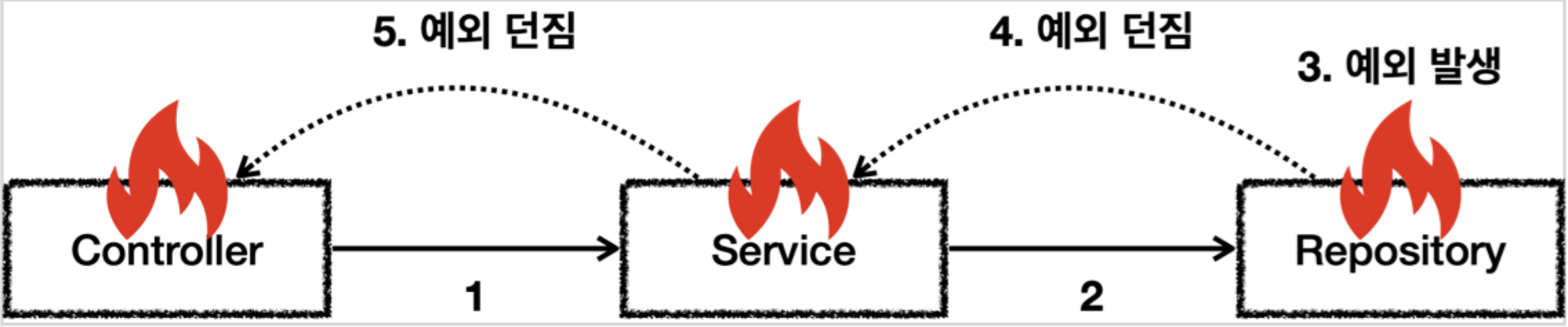
또한 예외를 잡거나 던질 때 지정한 예외뿐만 아니라 그 예외의 자식들도 함께 처리된다.
즉 Exception 을 catch 로 잡으면 그 하위 예외들을 모두 잡을수 있으며, Exception을 throws로 던지면 그 하위 예외들도 모두 던질수 있다.
Checked Exception, Unchecked Exception
Exception을 상속받는 두 예외의 가장큰 차이는 예외를 처리할 수 없을때 해당 예외를 밖으로 던지는 부분에 있다.
Checked Exception : 해당 예외를 처리할수 없다면 반드시 예외를 던져줘야한다.
Unchecked Exception: 해당 예외를 처리할수 없다해도 예외를 던져주지 않아도 된다.
public void callThrow() throws MyUncheckedException {
repository.call();
}
이런식으로 RuntimeException을 상속받는 MyUncheckedException의 경우 unchecked Exception인 RuntimeException을 상속받으므로, 반드시 throws 를 해줄 필요는 없다.
public void callThrow(){
repository.call();
}
즉 이렇게만 써도 된다는 소리다.
Checked Exception, Unchecked Exception을 언제 사용해야 하는가?
Checked Exception 같은경우는 예외가 발생했을때 반드시 잡아서 처리해야 하는 문제일 때만 사용한다.
예를들어 계좌 이체 실패 예외 같이 매우 심각한 문제는 개발자가 Unchecked Exception으로 둘경우 예외를 놓치는 경우가 발생할수 있기 때문에 체크 예외로 만들어 두면 컴파일러를 통해 놓친 예외를 인지할수 있다.
❗️지금 까지만 보면 체크 예외가 런타임 예외(체크 예외)보다 더 안전하고 좋아 보인다. (컴파일러가 해당 예외를 잡지 않았을때 검증을 해주므로) 하지만 체크 예외를 기본적으로 사용하면 발생하는 문제들은 아래와 같다.
Checked Exception의 문제점
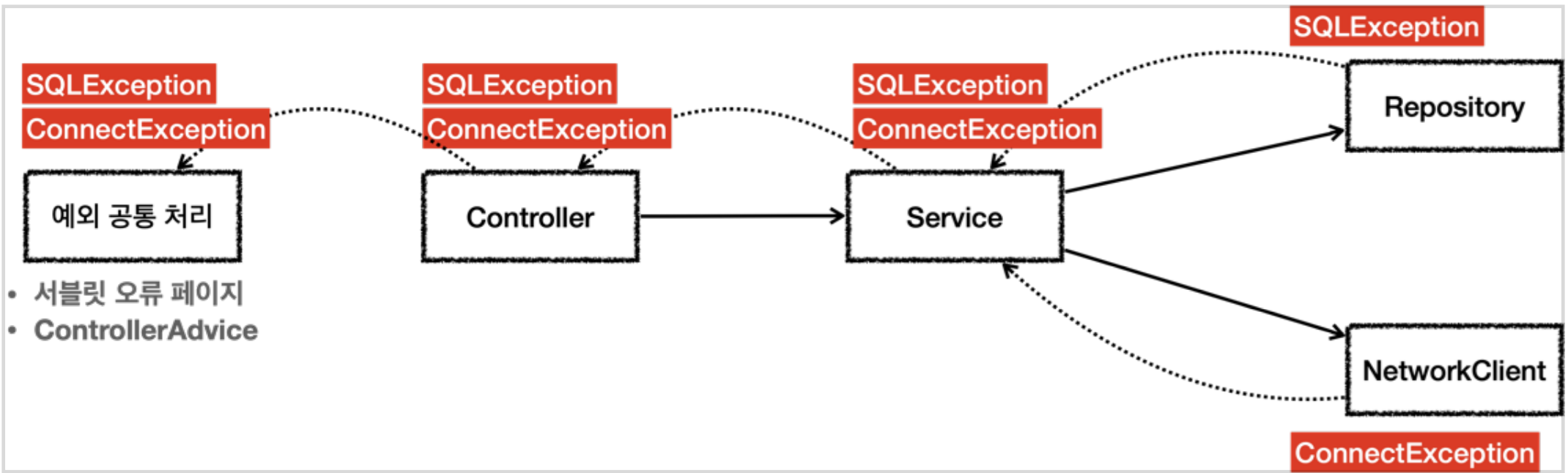
Repository 와 NetworkClient 는 각각 SQLException, ConnectException을 던진다. 이때 두 메서드를 호출하는 Service라는 곳에서 해당 예외를 처리할수 없다면, 두 예외가 계속해서 상위 클래스로 이동하게 된다.
결국 해당 예외는 ControllerAdvice에서 처리를 하게된다. 그후 웹 애플리케이션에서는 사용자에게 "서비스에 문제가 있습니다" 라는 일반적인 메시지를 보여준다.
즉 서비스 입장에서 알고싶지 않은 오류 내용(처리 불가능한)을 Checked Exception을 사용하므로써 강제적으로 알게된다는 문제점이 발생한다. 결론적으로 개발자가 예외를 던지는 시점에서 그것을 처리할 방법을 알 수 없는 경우 Unchecked Exception을 사용하는게 더 좋다는 뜻이다.
만약 Service, Controller 에서 처리할수 없는 (위에서 SQLException) 예외를 throws 하게 되면 어떠한 추가적인 문제점이 있을까?
가장 큰 문제점중 하나는 Service 또는 Controller에서 SQLException을 던지게 되면 해당 계층에서 java.sql.SQLException 에 의존하는 문제가 발생한다.
즉 우리가 추후 JPA를 사용하게 된다면 SQLException에 의존하던 모든 서비스, 컨트롤러의 코드를 JPAException 에 의존하도록 고쳐야 한다.
따라서 이런 예외 하나때문에 OCP,DI를 통해 클라이언트 코드의 변경 없이 대상 구현체를 변경할수 있다는 장점이 사라지게 된다.
만약 Checked Exception을 Unchecked Exception으로 변경한다면?
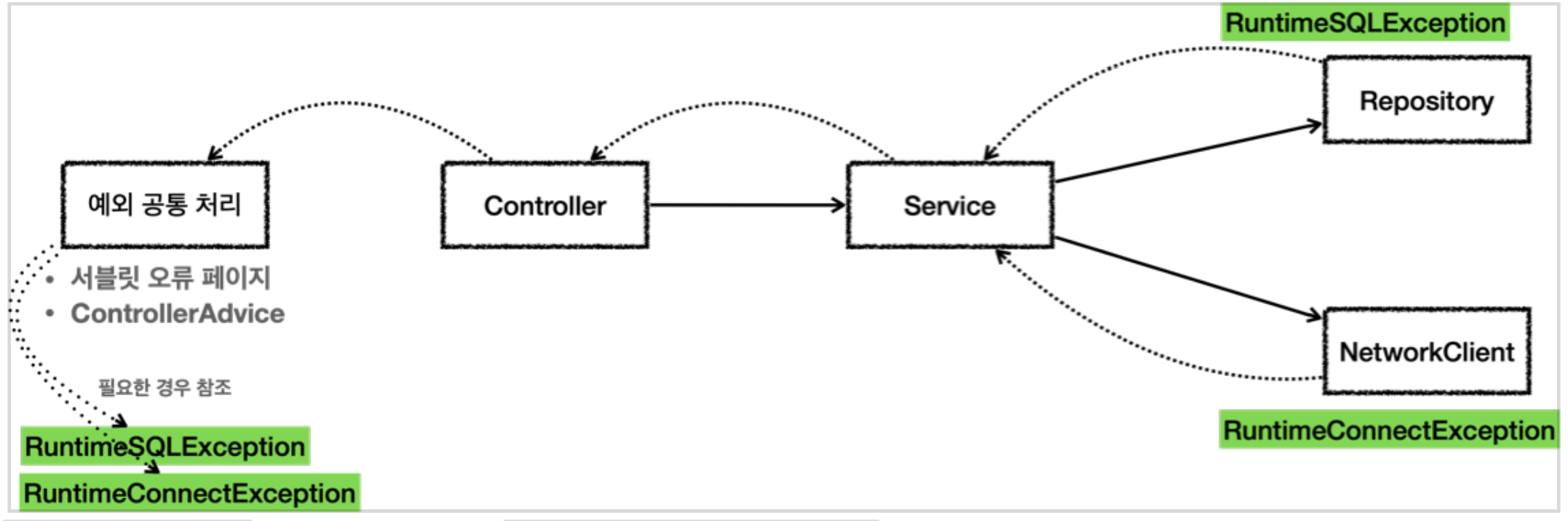
만약 위처럼 SQLException을 RuntimeException을 상속하는 RuntimeSQLException 을 던지게 해보자.
이렇게 UncheckedException을 던지는 경우 해당 예외를 처리할수 없는 Service 나 Controller 에서 해당 예외에 대한 내용을 알지 못하며, ControllerAdvice에서 해당 예외를 공통적으로 처리할수 있다.
또한 Checked Exception을 사용하며 발생했던 문제, Service 나 Controller가 해당 예외에 의존하는 문제 를 모두 해결할수 있다. 이렇게 하게되면 중간에 기술이 변경 되더라도 해당 예외를 사용하지 않는 Controller나 Service의 코드는 변경하지 않아도 된다.
❗️위처럼 RuntimeException을 사용하는게 더 좋다. 다만 주의할점은 개발자가 해당 예외를 놓치지 않도록 런타임 예외에 대한 문서화를 잘 해놔야한다.
예외 포함과 스택 트레이스
예외를 전환할 때 기존 예외를 포함해야 한다. 그렇지 않으면 스택 트레이스를 확인할 때 심각한 문제가 발생한다.
스택트레이스 출력방법
void printEx() {
Controller controller = new Controller();
try {
controller.request();
} catch (Exception e) {
log.info("ex", e);
}
}
이런식으로 log를 찍을때 마지막 파라미터에 예외를 전달하면 스택 트레이스를 출력할수 있다.
기존 예외를 포함하여 예외를 던지는 방법 (exception chaining)
public void call() {
try {
runSQL();
} catch (SQLException e) {
throw new RuntimeSQLException(e); //기존 예외(e) 포함
}
}
SQLException 이 발생했을때 RuntimeSQLException을 던져주는데 이때 e 를 포함하면 RuntimeSQLException을 catch할 때 원래의 SQLException에 대한 정보도 함께 얻을 수 있다.
13:10:45.626 [Test worker] INFO hello.jdbc.exception.basic.UncheckedAppTest - ex
hello.jdbc.exception.basic.UncheckedAppTest$RuntimeSQLException:
java.sql.SQLException: ex at
hello.jdbc.exception.basic.UncheckedAppTest$Repository.call(UncheckedAppTest.ja
va:61)
즉 예외를 다시 던질 때 원래의 예외를 인자로 넘겨줘야 상위 레이어로 예외를 전달하면서 원래의 예외 정보를 유지할수 있기 때문에 예외를 다시 던질때 원래의 예외를 인자로 넘겨주는 것을 잊으면 안된다.
데이터 접근 예외 직접 만들기
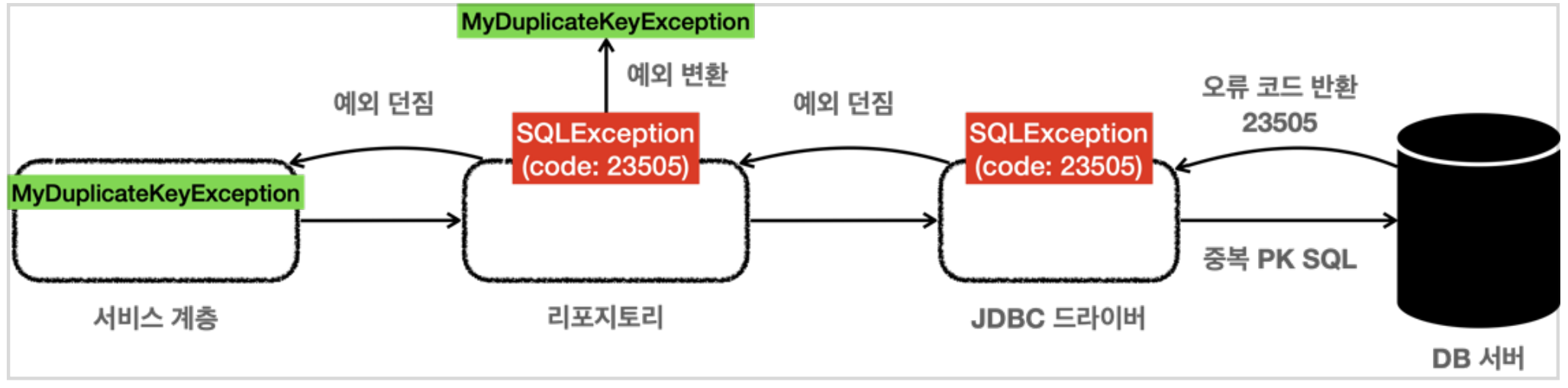
만약 위 그림처럼 특정 데이터 베이스의 예외를 복구하고 싶다고 가정해보자.
데이터를 DB에 저장할때 Unique 가 설정되어 있는 Column에 같은 값을 넣으려 한다면 JDBC 그라이버는 SQLException 을 던진다. 그리고 이 SQLException 에는 ErrorCode라는게 들어있다.
예를들어
e.getErrorCode() == 23505
위처럼 ErrorCode가 23505 라면 키 중복 오류 라는 것을 알수있고
ErrorCode가 42000 이라면 SQL 문법 오류 라는 것을 알수 있다.
❗️해당 ErrorCode는 DB마다 다르기 때문에 DB메뉴얼을 참고하자
만약 Repository에서 SQLException 이 발생한다면 우리가 직접 예외를 따로 만들어 Checked Exception인 SQLException을 만드는게 아닌 RuntimeException을 상속 받는 예외를 만들어 던져주면 된다.
근데 앞서 말했다 싶이 DB마다 ErrorCode는 모두 다르다. 즉 23505를 통해 키 중복 오류를 catch 한다하면, 그후에 DB가 변경되었을때 해당 ErrorCode를 모두 변경해야 한다는 문제점이 생긴다. 또한 ErrorCode는 매우 많다 따라서 해당 예외가 JDBC 에서 발생할때 마다 하나하나 체크를 해서 예외를 잡아줘야하는 문제가 발생한다. 이런 문제는 어떻게 해결해야 할까?
DB 마다 다른 ErrorCode를 해결하는 방법
스프링이 제공해주는 데이터 접근 예외 계층을 사용하면 해당 문제를 해결할 수 있다.
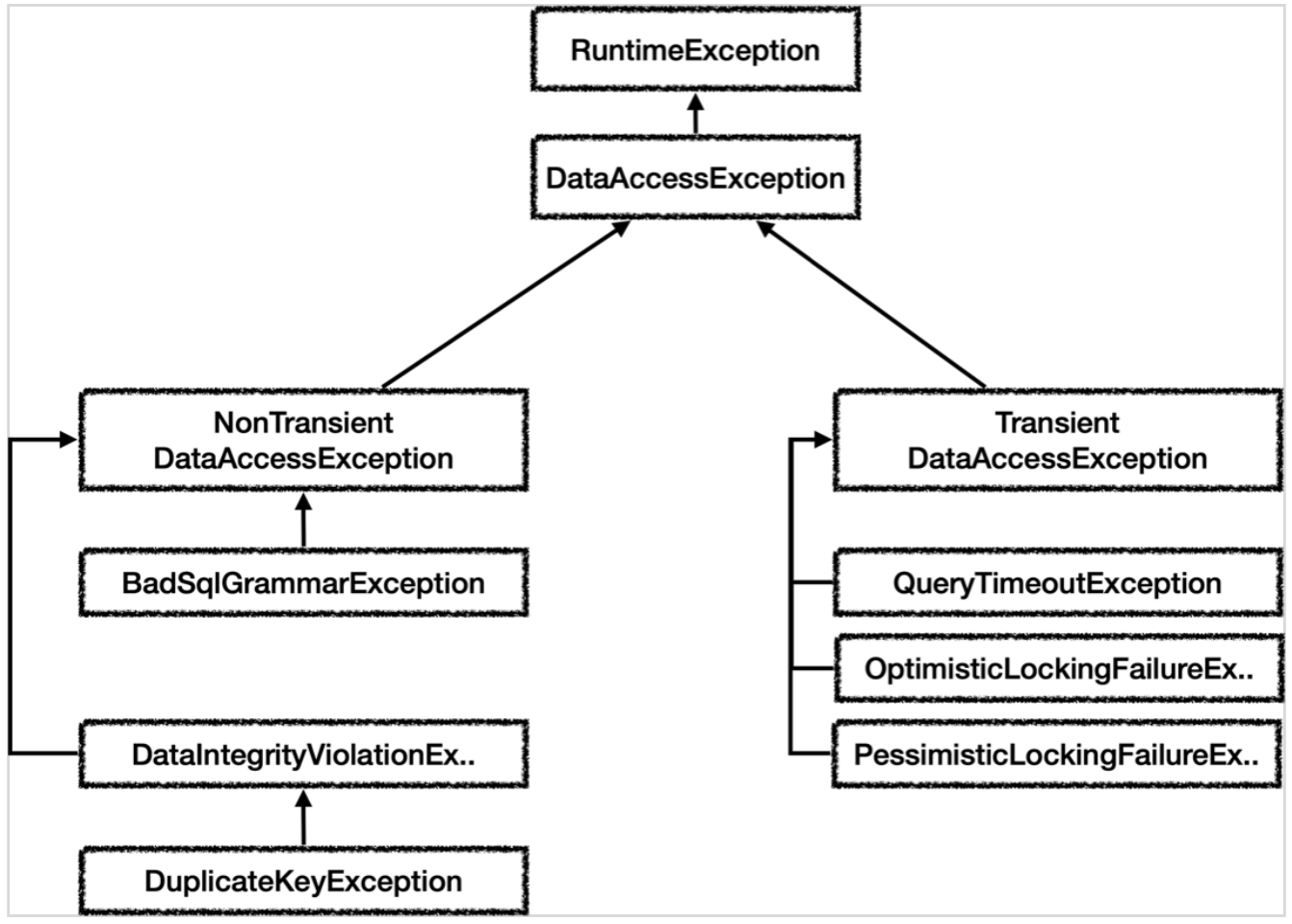
위 사진에서 DataAccessException은 Spring이 제공하는 데이터 접근 예외 계층의 최상위 이며, DataAccessException는 RuntimeException을 상속받기 때문에 Unchecked Exception이다.
또한 스프링에서 제공하는 예외는 특정 기술에 종속적이지 않다. 즉 JDBC 기술을 사용하든 JPA 기술을 사용하든 스프링이 제공하는 예외를 사용하면 된다.
즉 예를 들어 우리가 잘못된 sql 쿼리문 작성시 Spring에서는 BadSqlGrammarException 이라는 예외를 던져주는 것이다.
void exceptionTranslator() {
String sql = "select bad grammar";
try {
Connection con = dataSource.getConnection();
PreparedStatement stmt = con.prepareStatement(sql);
stmt.executeQuery();
} catch (SQLException e) {
assertThat(e.getErrorCode()).isEqualTo(42122);
//org.springframework.jdbc.support.sql-error-codes.xml
SQLExceptionTranslator exTranslator = new SQLErrorCodeSQLExceptionTranslator(dataSource);
//org.springframework.jdbc.BadSqlGrammarException
DataAccessException resultEx = exTranslator.translate("select", sql, e);
log.info("resultEx", resultEx);
assertThat(resultEx.getClass()).isEqualTo(BadSqlGrammarException.class);
}
}
extranslator.translate("select", sql, e)
- 첫번째 파라미터는 읽을수 있는 설명 (만약 save 기능을 하고있는 메서드에서 예외를 던지려면 "save"라 하면된다) 아무렇게나 우리가 알수 있게 설명을 적으면 된다.
- 두번째는 실행한 sql
- 세번째는 발생한 Exception
을 인자로 던져주면 resultEx을 통해 해당 예외가 어떠한 예외인지 알수 있다.
❗️결론
Service, Controller 같은 계층에서 예외 처리가 필요하다면 특정 기술에 종속적인 SQLException 과 같은 예외를 직접 사용하는 것이 아닌, 스프링이 제공하는 데이터 접근 예외를 사용하면 된다.
그니까 Repository에서 스프링이 제공하는 추상화된 예외를 던지고, Service 계층에서는 해당 예외를 catch 하면 된다.
Reference
'Spring' 카테고리의 다른 글
| redis를 통해 로그아웃 기능 구현 (0) | 2023.11.27 |
|---|---|
| Jasypt 를 통한 암호화 (2) | 2023.11.27 |
| Transactional을 통한 rollback시 AUTO_INCREMENT 초기화 문제 (0) | 2023.07.06 |
| @JdbcTest (0) | 2023.07.05 |
| @ActiveProfiles (0) | 2023.07.05 |
트랜잭션(transaction)
트랜잭션
데이터를 저장할때 DB에 저장하는 가장큰 이유중 하나는 DB는 트랜잭션이라는 개념을 지원하기 때문이다.
- A 계좌에서 출금
- B 계좌에 입금
@Transactional 애너테이션이 붙은 메서드에서는 해당 메서드 내의 모든 작업이 하나의 데이터베이스 트랜잭션 내에서 실행된다. 즉 위 와같은 예시에서 A의 계좌에서 출금이 된후 B계좌에 입금이 되는 작업을 하나로 묶어 처리한다는 뜻이다. 이 이유는 데이터 베이스 작업을 atomic으로 만들기 위함이다.
이때 1번 작업은 성공했는데 2번 작업이 실패한다면 롤백(Rollback)을 하면되고 1,2번 작업이 모두 성공하면 DB에 정상 반영하는 커밋(Commit)을 하게된다.
ACID
원자성(Atomicity) : 트랜잭션 내에서 실행한 작업은 모두 성공하거나 모두 실패해야한다.
일관성(Consistenct): 모든 트랜잭션은 일관성 있는 DB상태를 유지해야한다.
격리성(Isolation): 동시에 실행되는 트랜잭션들이 서로에게 영향을 미치지 않도록 격리한다.
지속성(Durability): 트랜잭션을 성공적으로 끝내면 그 결과가 항상 기록되어야 한다. 즉 중간에 문제가 발생하더라도 DB의 로그 등을 사용해 성공한 트랜잭션 내용을 복구해야 한다.
❗️격리성을 완전히 보장하려면 트랜잭션을 거의 순서대로 실행해야 한다. 이렇게 하면 동시 처리 성능이 매우 나빠진다. 따라서 이런 문제를 해결하기 위해 ANSI 표준은 트랜잭션의 격리 수준을 4단계로 나누어 정의하며 이 4단계중 한단계를 선택할수 있다.
트랜잭션 격리 수준 - Isolation level
READ UNCOMMITED(커밋되지 않은 읽기)
- 이 수준에서는 다른 트랜잭션에서 커밋되지 않은 변경사항(즉, 아직 확정되지 않은 변경사항)도 조회할 수 있다. 이를
Dirty Read라고 한다. - ex) 트랜잭션 A가 데이터 X를 수정하고 아직 커밋하지 않았다. 트랜잭션 B는 이 수정된(하지만 아직 커밋되지 않은) 데이터 X를 조회할 수 있다.
- 이 수준에서는 다른 트랜잭션에서 커밋되지 않은 변경사항(즉, 아직 확정되지 않은 변경사항)도 조회할 수 있다. 이를
READ COMMITTED(커밋된 읽기)
- 이 수준에서는 오직 커밋된 변경사항만 조회할 수 있다. 즉, 다른 트랜잭션에서 커밋되지 않은 변경사항은 보이지 않는다.
- ex) 트랜잭션 A가 데이터 X를 수정하고 아직 커밋하지 않았다. 트랜잭션 B는 이전 커밋된 상태의 데이터 X를 조회한다. A가 커밋한 후에 B가 다시 조회하면 변경된 X를 볼 수 있다.
REPEATABLE READ(반복 가능한 읽기)
- 이 수준에서는 트랜잭션이 시작될 때 조회한 데이터의 일관된 상태를 트랜잭션 내내 유지한다. 다른 트랜잭션이 해당 데이터를 변경하더라도, 이 트랜잭션에서는 변경사항이 반영되지 않는다.
- ex) 트랜잭션 A가 데이터 X를 조회한다. 이후 트랜잭션 B가 데이터 X를 변경하고 커밋한다. 하지만 트랜잭션 A는 여전히 최초 조회했던 시점의 데이터 X를 볼 수 있다.
SERIALIZABLE(직렬화 가능)
- 가장 엄격한 격리 수준으로, 트랜잭션들이 서로에게 아무런 영향을 주지 않는 것처럼 실행된다. 이 수준에서는 동시성이 크게 제한되며, 성능 저하가 발생할 수 있다.
- ex) 트랜잭션 A가 데이터 X와 Y를 조회한다. 이 수준에서는 트랜잭션 B가 X 또는 Y에 영향을 미치는 어떠한 작업도 수행할 수 없다. A가 완료될 때까지 B는 X나 Y와 관련된 작업을 수행할 수 없다.
아래로 내려갈수록 성능이 나빠지지만 더 안전하게 사용할수 있다.
이 강의는 READ COMMITTED(커밋된 읽기) 트랜잭션 격리 수준을 기준으로 설명한다고 한다.
데이터 베이스 연결 구조와 DB 세션
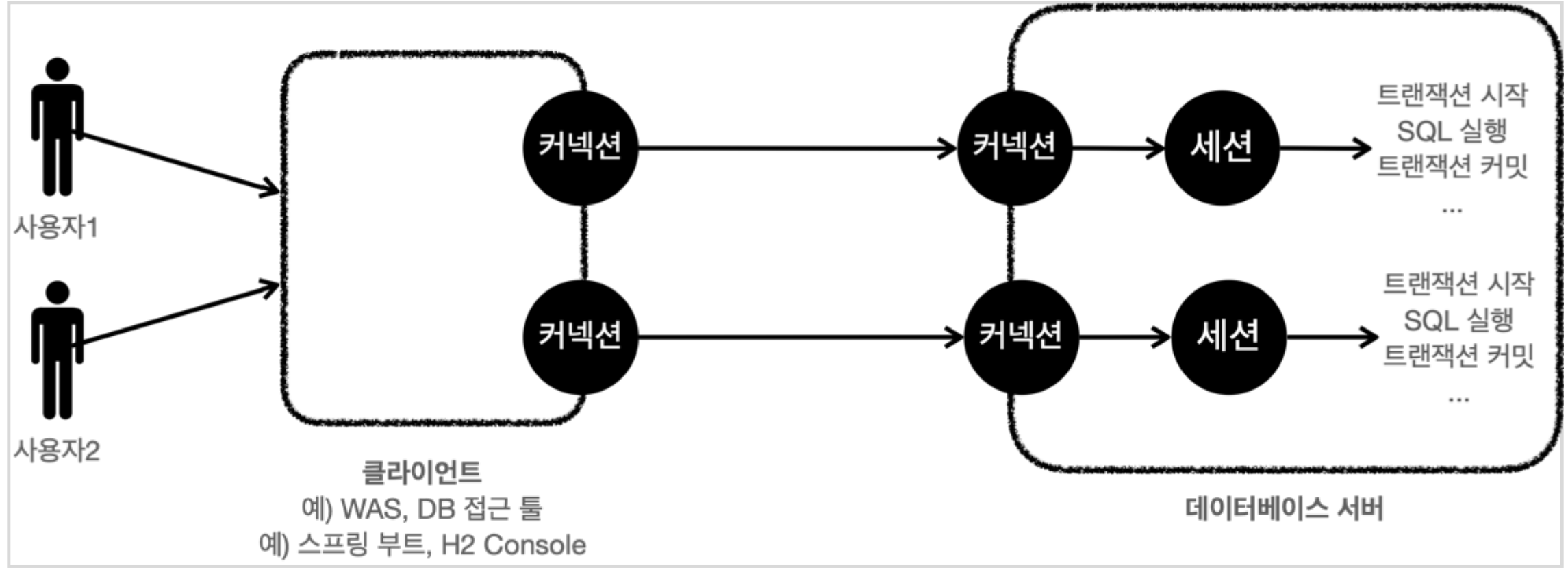
개발자가 클라이언트를 통해 SQL을 전달하면 현재 커넥션에 연결된 세션이 SQL 문을 실행하며, 이때 세션은 트랜잭션을 시작하고, 커밋 또는 롤백을 통해 트랜잭션을 종료한다. 그리고 이후에 새로운 트랜잭션을 다시 시작할수도 있다.
트랜잭션 개념 이해
데이터 변경 쿼리를 실행하고 그 결과를 반영하려면 커밋 명령어인 commit 을 호출하고, 결과를 반영하고 싶지 않으면 rollback 명령어를 호출하면 된다.
즉 commit 명령어를 호출하기 전까진 임시로 데이터를 저장한다. 따라서 해당 트랜잭션을 시작한 세션(사용자) 에게만 변경 데이터가 보이고 다른 세션(사용자)에게는 변경 데이터가 보이지 않는다.
Commit
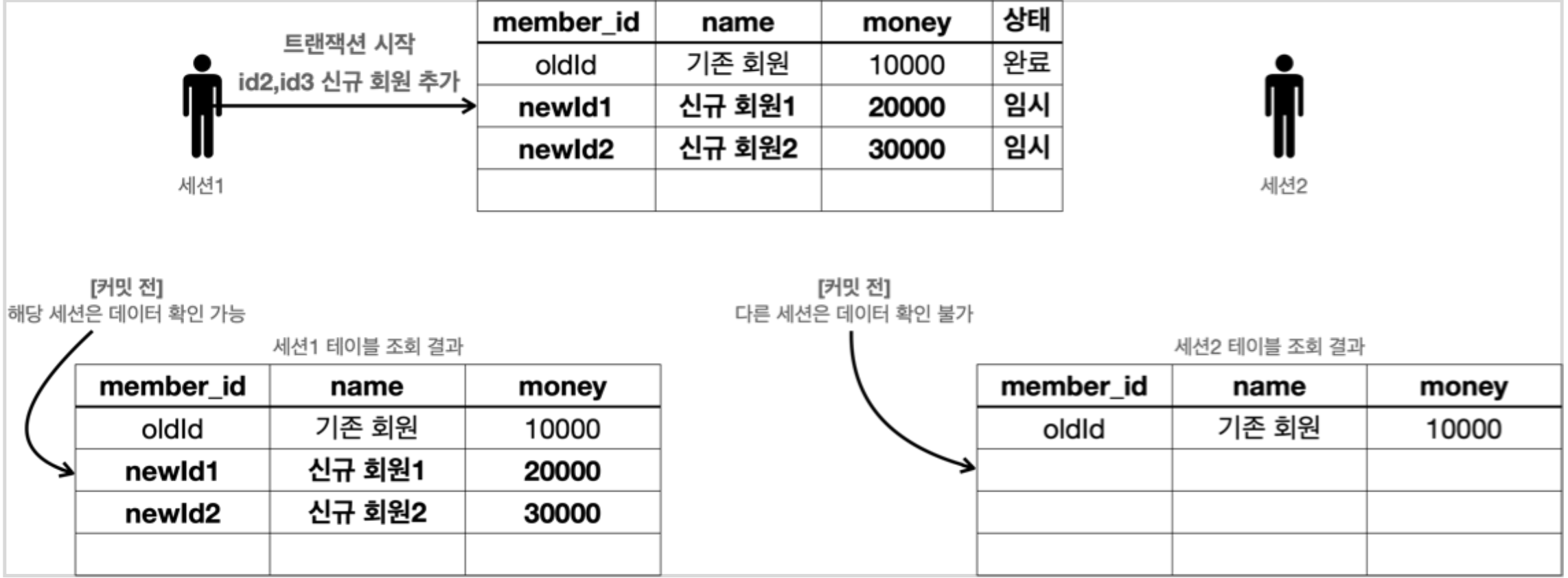
위처럼 세션1에서 신규 회원을 추가한다.
이때 commit 을 하지 않은 상태라면 세션2에서 테이블 조회를 한 결과는 오른쪽 table과 같다.
즉 세션1 에서 아직 commit 을 하지 않았으므로 세션 2에서 테이블 조회시 아직 신규 회원 데이터가 보이지 않는다.
그후 세션 1에서 commit 을 하게 된다면 그후엔 세션2에서도 테이블 조회시 추가된 신규 회원 데이터가 보이게 된다.
Rollback
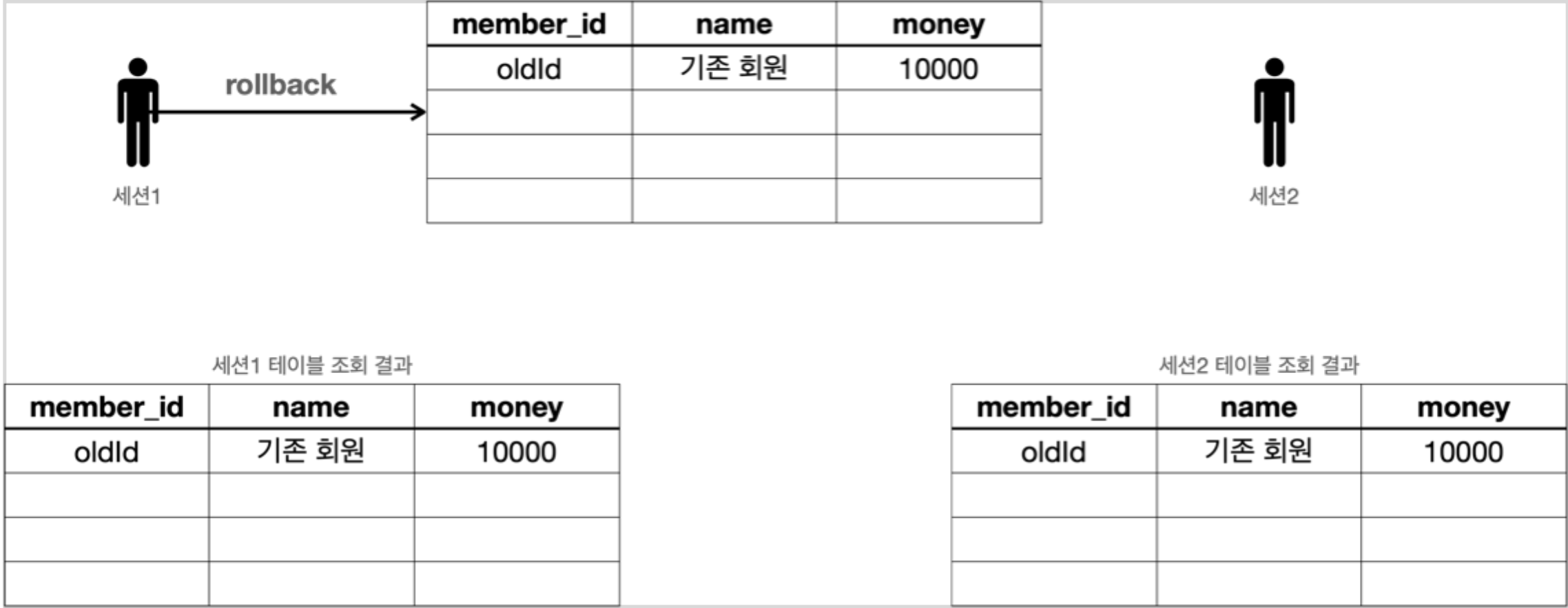
만약 Rollback 을 호출하게되면 트랜잭션을 시작한 상태로 돌아가게 된다.
즉 세션1이 DB에 반영한 모든 데이터가 처음 상태로 복구된다.
자동 커밋, 수동 커밋
트랜잭션 사용시 자동커밋 또는 수동 커밋을 설정할수 있다.
기본값은 자동 커밋이다.
자동 커밋 사용시 우리가 따로 설정할 필요없이 sql 문을 자동적으로 커밋해준다.
하지만 자동커밋 사용시 자동으로 커밋이 일어나버리기 때문에 트랜잭션 기능을 제대로 사용할수 없다.
수동커밋
set autocommit false; //수동 커밋 모드 설정
insert into member(member_id, money) values ('data3',10000);
insert into member(member_id, money) values ('data4',10000);
commit; //수동 커밋
위처럼 수동커밋을 설정해줄수있다. (관례상 수동커밋 설정이 트랜잭션의 시작을 의미한다.)
수동커밋을 설정하면 꼭 마지막에 commit 또는 rollback 을 호출해줘야 한다.
❗자동 커밋을 사용하면 결국 sql 문을 작성후 commit 또는 rollback 을 하더라도 아무런 일도 발생하지 않는다. (각각의 sql마다 자동적으로 commit이 되기 때문에)
DB 락
만약 세션1,2 가 동시에 어떠한 데이터를 동시에 수정하려한다면 트랜잭션의 원자성이 깨질수 있다.
이런 문제를 방지하기위해 하나의 세션이 특정 데이터를 수정하고 커밋이나 롤백 전까지 다른세션에서 해당 데이터를 수정할수 없게 막아야 한다.

이렇게 세션1이 세션2보다 먼저 락을 획득한다면, 세션1은 해당 row에 update를 할수있다.
이때 세션2또한 같은 데이터를 수정하기위해선 lock을 획득해야하지만 세션1이 먼저 lock을 획득후 동작하고 있으므로 세션1의 트랜잭션이 commit될때까지 기다려야한다.
❗️참고로 세션2가 무한정 기다리는건 아니다. 락 대기시간이 넘어가면 타임아웃 오류가 발생한다.
조회할때 lock을 사용하는 특수한 경우
조회는 기본적으로 세션1이 lock을 획득하고 데이터를 수정하고 있더라도 다른 세션에서 해당 데이터 조회를 할수있다.
만약 데이터를 조회하는데 다른 세션에서 해당 데이터를 조작하는걸 원치 않는다하면 select for update 구문을 사용하면 된다.
set autocommit false;
select * from member where member_id='memberA' for update;
위와같이 sql 구문을 작성한다면 다른 세션에서 해당 데이터를 조작할수 없게된다. (lock 을 가져와 해당 데이터의수정을 막는거기 때문에 조회까지 안되는건 아니다.)
결론적으로 select for update 구문을 사용하면, 내가 조회할때 다른 세션에서 해당 데이터를 조작할수는 없지만 조회는 가능하다.
Reference
'DB' 카테고리의 다른 글
| Docker를 통해 Mysql 설치 (1) | 2023.11.27 |
|---|---|
| h2 DB 연결 방법 (1) | 2023.11.27 |
| 커넥션 풀 및 데이터 소스 (0) | 2023.10.25 |
| JDBC (0) | 2023.10.25 |
| MySQL) 프로시저를 사용하여 더미 데이터 만들기 (0) | 2023.05.04 |